Java基础
集合类
Collection 和 Collections
Collection是一个集合接口,提供了对集合对象进行基本操作的通用接口,是list,set等的父接口。
Collections是一个包装类,包含各种有关集合操作的静态多态方法,此类不能实例化,就像一个工具类,服务于Collection框架。
常用集合类
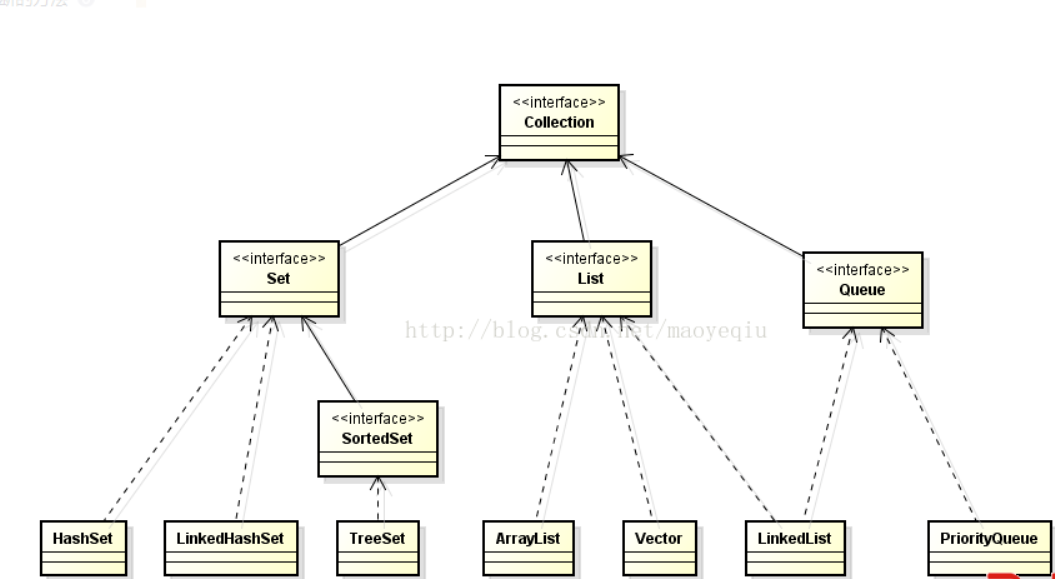
Set和List
Set和List都继承自Collection接口,都用来存储一组相同类型的元素。
list特点:元素有放入顺序,元素可重复。
set特点:元素无序,元素不可重复。
有些场景下set可以用来去重,set在元素插入时要方法来判断是否重复,这个方法决定了set中可以保存哪些元素
ArrayList & LinkedList & Vector
这三个都是List接口的实现。主要区别在于实现方式不同,对不同操作有不同的效率。
ArrayList本质是个可变数组,LinkedList是一个双链表,添加删除元素性能更好,查询拉跨。
Vector和ArrayList类似,但是属于强同步类,适用于多线程情况,如果代码本身线程安全,ArrayList更高效。
Vector和ArrayList 在添加更多元素时会请求更大空间,Vector每次请求双倍空间,ArrayList每次对size增长50%。
LinkedList还实现了Queue接口,该接口比List接口提供了更多方法,offer(),peek(),poll()等。
开发的时候注意,ArrayList的初始容量很小,如果预估数据较大,最好分配一个较大的初始值。
注意:使用Arrays.asList获得的list不可CRUD,因为这不是真正的List,用ArrayList的构造器可以转为真正的。
1 | List<Integer> fakeList = Arrays.asList(1, 2, 3); |
ArrayList Vector transient
ArrayList使用了transient进行优化而Vector没有,这是为啥。
查看ArrayList源码会发现elementData被transient修饰了,这是因为elementData可能长度比较长,但是只存放了几个数据,后面的都为null,这种情况下,序列化的时候不需要后面的空数据,于是将elementData使用transient修饰,并且定义了两个方法实现自己可控制的序列化:writeObject和readObject方法。
虽然Vector也实现了WriteObject方法,但是里面可以看到 data = elementData.clone();会拷贝null值。但是Vector时多线程下靠谱的数据结构。
什么是fail-fast:
fail-fast 机制是java集合(Collection)中的一种错误机制。它只能被用来检测错误,因为JDK并不保证fail-fast机制一定会发生。当多个线程对同一个集合的内容进行操作时,就可能会产生fail-fast事件。例如:当某一个线程A通过iterator去遍历某集合的过程中,若该集合的内容被其他线程所改变了;那么线程A访问集合时,就会抛出ConcurrentModificationException异常,产生fail-fast事件。
ArrayList的fast-fail:内部保存了一个modCount计数用来统计修改次数,还有一个expectedModCount用来保存当前线程修改次数,在遍历list的时候,在next方法里会调用checkForComodification方法查看是否合法,如果modCount!=expectedModCount 说明有其他线程动过数组了 那么就抛出异常。
synchronizedList和Vector
Vector来自java.util ,synchronizedList来自java.util.collections的一个静态内部类。
多线程的时候可以用Vector也可以用Collections.synchronizedList(List list)来返回一个线程安全的List
SynchronizedList的底层操作:
1 | public void add(int index, E element) { |
可以看到对于add方法,实际上只是在外面包了一个同步块。
- SynchronizedList有很好的拓展和兼容功能,它可以将所有的List子类转化为线程安全的类(ArrayList和LinkedList等)
- 使用SynchronizedList的时候,遍历时要手动进行同步处理
- SynchronizedList可以指定锁定的对象
Set如何实现元素不重复
Set有两个,HashSet和TreeSet
TreeSet使用二叉树实现,底层是TreeMap的keySet(),TreeMap里面是红黑树,所以数据都是自动排好序的不可以放入null。元素在插入TreeSet的时候调用compareTo() 方法,所以TreeSet中要实现Comparable接口。
HashSet根据哈希表实现,基本操作都是由HashMap实现的,向HashSet添加元素的时候先计算元素的hashCode,然后计算出这个元素的存储位置,为空就添加进去,不为空则调用equals方法,看是否相等,相等就不添加,否则调用冲突算法继续。
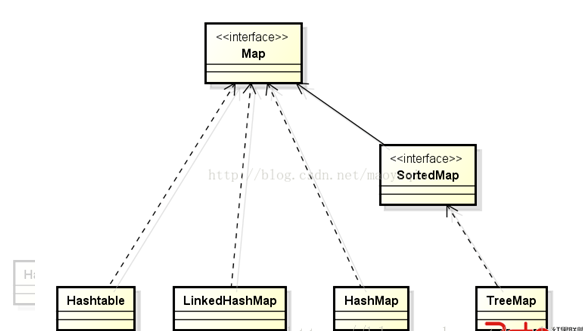
HashMap HashTalbe ConcurrentHashMap
HashMap和HashTable区别:HashTable的方法是同步的所以HashTable线程安全。HashTable中KV都不可以null,而在HashMap中null可以作为键(只能存在一个)但是值可以有多个为null
HashTable中的hash数组大写初始是 11 增加方式:old*2+1
HashMap默认大小 16 每次扩容为2的指数 16
HashTable直接使用对象的HashCode,HashMap重新计算hash值
HashMap和ConcurrentHashMap:后者线程安全
HashMap
HashMap实际上是将数组和链表组合在一起,每一个数组后面挂着一个链表,哈希碰撞的元素挂在同一个链表。
HashMap的容量:默认情况下大小是16,如果用户手动指定大小则会选择大于这个数的一个2次幂。7-》8。
什么时候扩容:
HashMap里面定义了size 表示一个数组的链表存放元素个数,capacity 总容量,loadFactor 装载因子,其实就是百分比(默认0.75)。threshold就是临界值,如果超过 threshold = loadFactor*capacity 那么就扩容。所以对于默认大小16的HashMap >12的时候就扩容了。
怎么扩容:
每次扩容都要将内部所有元素重新Hash重新分配元素到相应的桶,如果只是简单增加容量的话,get的时候对新的容量取模的数不是原来存的数就会找不到存入的数。
先介绍个技巧:如何提高取模效率,用位运算&替换取模%。这要求被取模数为2的幂
10 % 8 = 2; 10 & 8 = 2;
那么为什么HashMap的容量一定要是2的幂呢?
这是因为一个元素存入HashMap,放入里面哪个桶之前肯定要知道数组下标,这个下表就是hash值对数组容量取模,所以为了取模运算快点,需要被取模数为2的幂。
为啥loadFactor不是1而是0.75呢?
假设负载因子为 1,默认最大容纳数量16,16满了才要扩容,如果这16个数分别存放在各个数组是最好的,但是显然,数据越多的时候,碰撞的概率越大。如果是0.75的话,13个就要扩容了,那么这12个数据碰撞的概率很显然小于16个数的碰撞概率。所以12的时候扩容是比较好的。0.75这个数字被认为是合理的,因为0.7左右数据的碰撞概率最低。
HashMap设置多少初始值合适?
如果不设置初始值,且目标数据过大的话,每次扩容都会全部重排内部元素,造成浪费。
传递的数据如果不是2的幂则会选择一个大于输入值的2的幂,在设置的时候要考虑到负载因子,举个反例:如果输入7 那么自动计算出大小为8,但是负载因子是0.75 也就是6个以后就会扩容,这显然是不科学的,现在比较推荐的算法是:预计大小/0.75 +1 = 设置大小。如放入7,7/0.75 +1 = 10.3 会被计算为 16
如何遍历集合类 Collection
- 普通for循环
- 增强for循环
- iterator迭代
- stream迭代
1 | Iterator it = list.iterator(); |
- Enumeration:这个比较古老,只能遍历Vector,HashTalbe这些古老集合。不建议使用。
为什么不能一边遍历集合一边增删
首先集合类都有个fast-fail机制,这个前面讲过了,那么在for循环中,如果使用add方法添加元素,会修改modCount 这是实际修改值,一般一个list生成的时候是0,还有个expectedModCount 这是Iterator的成员变量,只有通过迭代器操作这个值才会变化,一般这两个值是相等的。在遍历的时候如果调用了list.remove(xx)而不是iterator.remove()的话,只会修改modCount,下次遍历的时候会调用这个方法:
1 | final void checkForComodification() { |
发现不一样抛出异常(ConcurrentModificationException)。
fail-safe:Java提供了一些安全的集合类,这样的集合在遍历时不是在集合内容上访问的,而是copy一个在复制体上遍历,java.util.concurrent包下的都是fail-safe的。可以在多线程下使用,也可以foreach中add/remove。
1 |
|
COW Copy-On-Write
了解COW后会好奇,为啥都已经上锁了还要拷贝,直接操作原链表不好吗。这个Vector没啥区别啊感觉。
但其实不是,COW只有在写的时候会上锁,而且所有操作不是对原链表操作,而是对复制的容器进行操作,到需要写入的时候,上锁,将原链表的指针指向复制的链表。读的时候是不上锁的。
当然也有缺点:
读的方法不加锁,或者读取的是修改前的数据,毕竟一个在读,可能有一个在写。
要拷贝,如果数据量大那就崩了,所以还是慎用
一般COW用于读多写少的场景,比如读取白名单,商品类目访问和更新
枚举
switch 支持枚举类型(之前讲过switch只支持int整型,其实这里也是,只是将enum转为switch(xx.ordinal())),枚举可以实现接口,枚举类不能被继承。
枚举定义
常量
1
2
3public enum Season {
SPRING,SUMMER,AUTUMN,WINTER
}绑定值
1
2
3
4
5
6
7
8
9
10
11
12public enum Season {
SPRING(1), SUMMER(2), AUTUMN(3), WINTER(4);
private int code;
private Season(int code){
this.code = code;
}
public int getCode(){
return code;
}
}绑定值和名
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33public enum Color {
RED("红色", 1), GREEN("绿色", 2), BLANK("白色", 3), YELLO("黄色", 4);
// 成员变量
private String name;
private int index;
// 构造方法
private Color(String name, int index) {
this.name = name;
this.index = index;
}
// 普通方法
public static String getName(int index) {
for (Color c : Color.values()) {
if (c.getIndex() == index) {
return c.name;
}
}
return null;
}
// get set 方法
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getIndex() {
return index;
}
public void setIndex(int index) {
this.index = index;
}
}
枚举实现单例
双重校验锁
1 | public class Singleton{ |
枚举:
1 | public enum Singleton{ |
枚举和线程安全
非枚举方式都要求自己实现线程安全,如同双重校验锁,枚举Java本身在底层实现了线程问题。
在一个类真正被使用的时候,静态资源的初始化,类的加载和初始化过程都是线程安全的,所以,创建一个enum类是线程安全的
双重校验锁可能会被序列化锁破坏,普通的Java类的反序列化中,会通过反射的方式调用类的默认构造函数来初始化对象,所以即使单例的构造函数私有,也会被破坏,由于反序列化后的对象是重新new出来的,这就破坏了单例。而enum的序列化只是将枚举对象的name属性输出到结果。
枚举的比较
equals 和 == 没区别,compareTo只是比较enum的ordinal顺序大小