基础
Java序列化
序列化是将对象转换为可传输格式的过程,是一种数据持久化手段,一般广泛应用于网络传输,RMI和RPC场景。
反序列化就是逆操作,Java序列化特指JDK的序列化实现,这个实现不同于JSON序列化,是不跨语言的。
Java对象的序列化
Java内创建的对象都是存在于JVM的堆内存中,只有JVM处于运行态这些对象才会存在,一旦JVM停止运行,这些对象状态也随之消失。但是在真是场景中我们需要将这些对象持久化下来,并且在需要的时候将对象重新读取出来。对象序列化可以很容易的在JVM中的活动对象和字节数组之间进行调换。
Serializable接口
类通过实现java.io.Serializable接口以启用其序列化功能,当对一个对象进行序列化的时候,如果遇到不支持Serializable接口的对象,会抛出 NotSerializableException。
配置实体类
1 | import java.io.Serializable; |
序列化实体类
1 | public class SerializableDemo1 { |
Externalizable接口
Externalizable继承了Serializable接口,且定义了两个新的方法:writeExternal()和readExternal(),使用Externalizable接口进行序列化的时候要重写writeExternal()和readExternal()方法。
serialVersionUID
序列化时将对象状态信息转为可存储或可传输的形式,虚拟机是否支持反序列化不仅取决于类的路径和代码一致,还要求两个类的序列化ID是否一致,即serialVersionUID
反序列化时:JVM将传递过来的serialVersionUID与本地对应的实体类的UID进行比较,相同即可反序列化。
这样是为了安全,因为文件存储的内容可能被篡改。
Java序列化缺陷
不能跨语言,如果两个不同语言编写的程序进行通讯,用Java序列化是无法完成序列化和反序列化的。
不安全,Java的反序列化实质是通过ObjectInputStream类调用readObject()方法实现的,这个方法本质是个构造器,可以将实现了Serializable接口的类都实例化,所以在反序列化过程中该方法会执行任意代码。
以下是攻击代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14Set root = new HashSet();
Set s1 = root;
Set s2 = new HashSet();
for (int i = 0; i < 100; i++) {
Set t1 = new HashSet();
Set t2 = new HashSet();
t1.add("test"); //使t2不等于t1
s1.add(t1);
s1.add(t2);
s2.add(t1);
s2.add(t2);
s1 = t1;
s2 = t2;
}创建循环对象链,然后将序列化后的对象传输到程序中反序列化,这种情况会导致 hashCode 方法被调用次数呈次方爆发式增长, 从而引发栈溢出异常。
序列化后的流很大
序列化性能差 太慢
序列化对单例的破坏
实现一个双重校验锁的单例,对其序列化再反序列化,查看是否同一个对象。
双重校验锁单例看上一篇
验证:
1 | public static void main(String[] args) throws IOException, ClassNotFoundException { |
如何解决反序列化对单例的破坏呢:在单例类中定义readResolve即可添加方法到单例中:
1 | private Object readResolve() { |
原理:调用栈挺多的,实质就是在底层方法里有个判断目标对象是否有readResolve方法,如果有,就通过反射的方式调用readResolve方法返回一个对象用于反序列化最终返回对象。所以单例的readResolve方法直接返回自身。
Apache-Commons-Collections的反序列化漏洞
这个漏洞只出现在3.2.1版本以下
复现
Commons Collections中提供了一个Transformer接口,主要是用来进行类型转换,这个接口有一个实现类:InvokerTransformer,里面有个transform方法,核心代码就三行,通过反射将传入的对象进行实例化。然后执行其iMethodName方法。
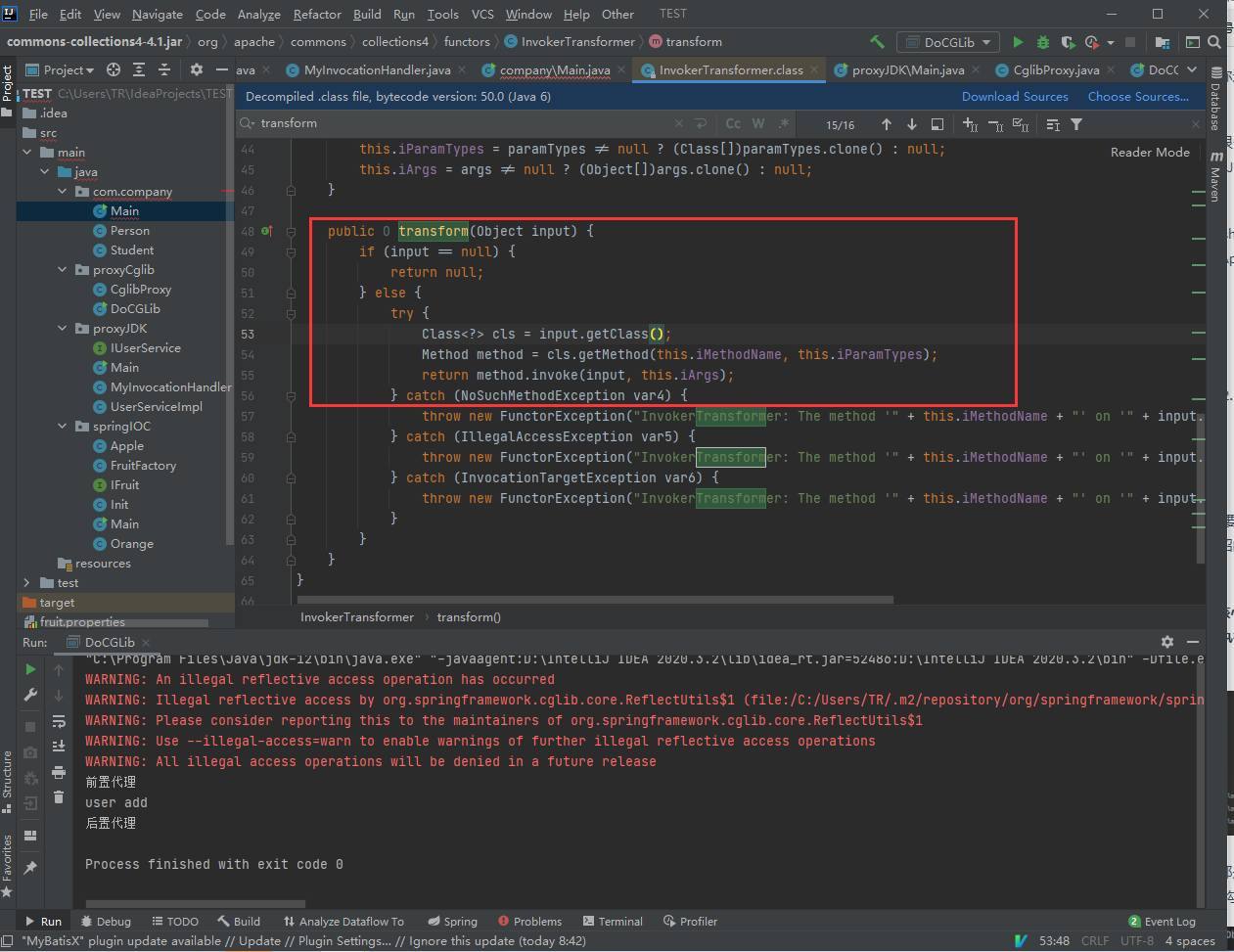
注解
元注解
定义其他注解的注解
元注解有六个:@Target(表示该注解可以用于什么地方)、@Retention(表示再什么级别保存该注解信息)、@Documented(将此注解包含再javadoc中)、@Inherited(允许子类继承父类中的注解)、@Repeatable(1.8新增,允许一个注解在一个元素上使用多次)、@Native(1.8新增,修饰成员变量,表示这个变量可以被本地代码引用,常常被代码生成工具使用)。
Java常用注解
@Override 表示覆写父类方法
@Deprecated 表示当前方法已过时
@SuppressWarnings 表示关闭一些警告信息
@SafeVarargs 表示专门为抑制堆污染警告提供的
@FunctionalInterface 表示用来指定某个接口必须是函数式接口
Spring常用注解
@Configuration:会将一个类作为IoC容器,它的某个方法头上如果注册了@Bean就会作为这个Spring容器中的Bean。
@Scope 作用域
@Lazy(true) 延迟初始化
@Service 标注业务层组件
@Controller 标注控制层组件
@Repository 标注数据访问组件,即DAO组件
@Component 泛指组件,当组件不好归类的时候可以用这个注解
@PostConstruct用于指定初始化方法(用在方法上)
@PreDestory用于指定销毁方法(用在方法上)
@DependsOn:定义Bean初始化及销毁时的顺序
@Primary:自动装配时当出现多个Bean候选者时,被注解为@Primary的Bean将作为首选者,否则将抛出异常
@Autowired 默认按类型装配,如果我们想使用按名称装配,可以结合@Qualifier注解一起使用。如下: @Autowired @Qualifier(“personDaoBean”) 存在多个实例配合使用
@Resource默认按名称装配,当找不到与名称匹配的bean才会按类型装配。
@PostConstruct 初始化注解
@PreDestroy 摧毁注解 默认 单例 启动就加载
如何定义注解
注解和接口的定义差不多,注解多了个@符号
1 |
|
可以定义成员变量,还可以添加默认值,实例如上。
Target: 指定注解修饰什么东西(类,方法,字段)
Rentention: 指定修饰的注解保留多长时间,分别SOURCE(注解仅存在于源码中,在class字节码文件中不包含),CLASS(默认的保留策略,注解会在class字节码文件中存在,但运行时无法获取),RUNTIME(注解会在class字节码文件中存在,在运行时可以通过反射获取到)三种类型,* 如果想要在程序运行过程中通过反射来获取注解的信息需要将Retention设置为RUNTIME !*
Documented:指定被修饰的注解类将被javadoc工具提取成文档。
Inherited:指定注解是否有继承性
通过反射使用自定义注解
如何获取类的方法,字段上的注解,以及获取注解的值:
1 | Class<?> clz = bean.getClass(); |
实体类:
1 |
|
获取注解
1 | public class MyTest { |
泛型
泛型是JDK5引入的新特性,允许在定义类和接口的时候使用类型参数。
泛型最大的好处是复用,比如一个List接口,可以将String,Integer等类型放入,如果不用泛型,存String要写一个对应的接口,使用泛型就可以解决这个问题。
Java的类型擦除
Java语言中的泛型只在程序源码中存在,在编译后的字节码文件中,就已经被替换为原来的原生类型(Raw Type,也称为裸类型)了,并且在相应的地方插入了强制转型代码,因此对于运行期的Java语言来说,ArrayList
类型擦除指的是通过类型参数合并,将泛型类型实例关联到同一份字节码上。编译器只为泛型类型生成一份字节码,并将其实例关联到这份字节码上。类型擦除的关键在于从泛型类型中清除类型参数的相关信息,并且再必要的时候添加类型检查和类型转换的方法。 类型擦除可以简单的理解为将泛型java代码转换为普通java代码,只不过编译器更直接点,将泛型java代码直接转换成普通java字节码。 类型擦除的主要过程如下: 1.将所有的泛型参数用其最左边界(最顶级的父类型)类型替换。 2.移除所有的类型参数。
eg
code:
1 | public static void main(String[] args) { |
反编译:
1 | public static void main(String[] args) { |
可以看到泛型类型都转为了基本类型
泛型带来的问题
泛型不可重载
1 | public class GenericTypes { |
代码中可以看到,两个重载函数唯一区别是List<String> 和 List<Integer> 但是在编译后泛型类型都会被擦除变为原始类型,导致两个方法变为一样的方法,所以编译不通过。
泛型的catch
还是由于类型擦除问题,catch多个自定义泛型类的时候可能会重复。
泛型的静态变量
1 | public class StaticTest{ |
答案是——2!由于经过类型擦除,所有的泛型类实例都关联到同一份字节码上,泛型类的所有静态变量是共享的。
使用泛型注意点总结
泛型本质就是一个java提供的语法糖,在虚拟机中只有普通类和普通方法,所有泛型类的类型参数在编译的时候都会被擦除
创建泛型对象的时候要指明类型让编译器尽早做参数检查。
所有静态变量是被泛型类的所有实例共享的
泛型的类型参数不能用在catch里
尽量不要使用原始态类型(Map 不指定泛型类型)可能导致ClassCastException
使用泛型
限定通配符和非限定通配符
- :可以赋值给任意T及T的子类集合,上界为T,取出来的类型带有泛型限制,向上强制转型为T。null 可以表示任何类型,所以null除外,任何元素都不得添加进集合内。
- : 可以复制T及任何T的父类集合,下界为T。再生活中,投票选举类似于的操作。选举投票时,你只能往里投票,取数据时,根本不知道时是谁的票,相当于泛型丢失。
1 | public class Food {} |
<? extends Fruit>虽然不能添加元素,但可以在初始化的时候,接受一个已经定义好的list,而该list存放的类型一定相同,因此,List<? extends T>可直接接受一个定义好的list。
<? super T>:专门用来存,存的数据只能是本身或者子类,指向的时候只能指向父类
<? extends T>: 专门用来消费,得到的类型都是本身,指向的时候只能指向子类
异常
自定义异常最好继承Exception
try-with-resources
一般操作文件io,数据库链接比较耗费资源,用完后应该及时关闭,一般我们是在try catch finally的finally里面调用close方法释放资源。
但是从jdk7开始提供了更好的方法:try-with-resources,新的syntax sugar,在try后面接上对io流的定义即可。
1 | public static void main(String... args) { |
finally和return的执行顺序
假如try里面有个return 那么后面的finally会不会执行,什么时候执行?
如果try里有return 那么finally的代码还是会执行,return表示整个方法的返回,所以finally会在return之前执行。
但是return前执行的finally块内,对数据的修改效果对于引用类型和值类型会不同
1 | // 测试 修改值类型 |
时间
SimpleDateFormat的线程安全问题
强制:SimpleDateFormat 是线程不安全的,一般不要定义为static变量,如果定义static变量必须加锁或者使用DateUtils工具类。
Date类型转为String并且指定输出格式:
1 | // Date转String |
String 转Date:sdf.parse(dataStr);
时区问题:由于存在时区,不同地区时间不同,可以在代码中手动设置时区,获得当地时间,如中国的时间是GTM+8
1 | SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); |
为什么会导致线程不安全?:
因为观察源码可以发现,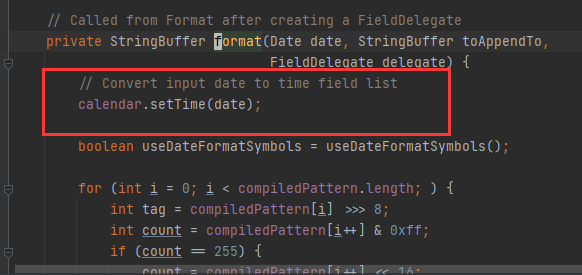
calendar.setTime(date)是没有线程安全保证的,所以当设置SimpleDateForat为静态变量时,所有子线程都可以访问,可能A线程刚刚设置完calendar.setTime(date)就被B线程再调用修改时间了。
如何解决?
使用局部变量。
或者一定要将SimpleDateFormat作为共享变量的话,加同步锁。
synchronized(simpleDateFormat){...或者使用使用ThreadLocal
1 | /** |
如果是Java8. 换成DateTimeFormatter即可,线程安全。
为什么选择ThreadLocal
ThreadLocal使同一变量在每一个线程中有各自的副本,不就意味着这个变量是不共享数据的,那不共享数据的话,为什么我不把这个变量变成自定义线程类的成员域,如果可以,ThreadLocal类的作用是啥?
Spring采用Threadlocal的方式,来保证单个线程中的数据库操作使用的是同一个数据库连接,同时,采用这种方式可以使业务层使用事务时不需要感知并管理connection对象,通过传播级别,巧妙地管理多个事务配置之间的切换,挂起和恢复。
其实本质是将变量的值都存在thread中,为什么不将变量定义为线程的成员变量呢,还是因为资源节省,每个线程都用成员变量而不用单例的话会造成大量浪费。而且假如有链路的话,需要共享一些变量比如用户信息,这时候如果定义成线程成员变量,那么不同线程请求得将信息传递过去,但是如果使用静态变量那么直接import后不需要传参直接threadlocal获取。
Java8时间处理
在Java8中, 新的时间及⽇期API位于java.time包中, 该包中有哪些重要的类。 分别代表了什么?
Instant: 时间戳
Duration: 持续时间, 时间差
LocalDate: 只包含⽇期, ⽐如: 2016-10-20
LocalTime: 只包含时间, ⽐如: 231210
LocalDateTime: 包含⽇期和时间, ⽐如: 2016-10-20 231421
Period: 时间段
ZoneOffset: 时区偏移量, ⽐如: +8:00
ZonedDateTime: 带时区的时间
Clock: 时钟, ⽐如获取⽬前美国纽约的时间
新的java.time包涵盖了所有处理日期,时间,日期/时间,时区,时刻(instants),过程(during)与时钟(clock)的操作。
获取当前时间
1 | LocalDate today = LocalDate.now(); |
创建指定日期
LocalDate date = LocalDate.of(2018, 01, 01);
格式化时间+时间戳转换
1 | LocalDateTime localDateTime = Instant.ofEpochMilli(1617257935413L).atZone(ZoneOffset.ofHours(8)).toLocalDateTime(); |
闰年判断
1 | LocalDate nowDate = LocalDate.now(); |
计算日期间天数和月数
Period period = Period.between(LocalDate.of(2018, 1, 5),LocalDate.of(2018, 2, 5));