Docker compose
官方学习文档
出现的原因
DockerFile有了以后,build,run只针对一个容器,效率不高,如果多个服务之前存在依赖关系很麻烦
Docker Compose 是用来定义和运行多个容器的应用,使用yaml配置文件
正常使用有三个步骤:
- 定义应用的环境(Dockefile)
- docker-compose.yml 用来定义服务
- 运行 docker compose up 启动项目
这个其实也就比自己手动写脚本好用,还是很局限,本质是脚本方式启动电脑上的一些服务
对于docker compose的一些说明
如果使用的是官方示例可以发现启动的容器名字是文件夹的名字+副本数量
会默认创建对应的 文件夹_default的网络,yml配置文件内定义的若干个服务启动后,这些服务都在同一个网络下,之后互相访问可以直接通过容器名访问
yml 规则
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| # 3层
version : '' #版本
service : #服务
service1:web
images:
build:
volume:
...
service2:redis
depends_on:
- db
- redis
# 其他配置 网络 卷 全局规则
volumes:
network:
configs:
|
一些重要的参数的详情
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
| # 启动的时候是有一个启动顺序的,需要保证其他服务器启动
depends_on:
- db
# db 这里指的是自己定义的服务名
# image: 这里指的是镜像import的基础镜像
services:
db:
image: postgres
services:
web:
# 指令执行 镜像构建成功后执行的命令
command: python manage.py runserver 0.0.0.0:8000
# 构建 根据当前目录的dockerfile文件构建这个镜像
build: .
# 暴露的端口 本地8000 容器5000
ports:
- "8000:5000"
# 挂载卷,启动docker的目录,映射到容器的code目录
volumes:
- .:/code
# 环境变量设置
environment:
FLASK_ENV: development
# volume 还有其他挂载方式 具名挂载
services:
db:
image: mysql:5.7
volumes:
- mysql_db_data:/var/lib/mysql
# 需要单独声明具名挂载的卷 其实是为了多个容器公用数据
volumes:
mysql_db_data: {}
wordpress_data: {}
|
springboot实例
以公司的spring项目为例,首先确保java -jar没有问题,但是我maven打包后执行java -jar自动退出,打开日志详细发现没有指定yml配置文件的问题,通过java -jar -Dspring.config.location=./application.yml,./application-local.yml phm-admin.jar 且拷贝两个配置文件到本地才成功。
编写这个springboot的镜像吧,基于java8
1
2
3
4
5
6
| FROM java:8
COPY target/phm-admin.jar /app.jar
COPY src/main/resources/*.yml ./
CMD ["--server.port=8080"]
EXPOSE 8080
ENTRYPOINT ["java","-jar","-Dspring.config.location=./application.yml,./application-local.yml","app.jar"]
|
成功后编写对应的docker-compose文件
1
2
3
4
5
6
7
8
9
10
11
| version: "3.9"
services:
web:
build: .
ports:
- "8080:8080"
depends_on:
- redis
redis:
image: "redis:alpine"
|
注意要修改配置文件,把依赖的redis的地址改为redis,这里用的是redis的主机名
DockerSwarm
Docker swarm控制服务器物理集群(加入离开锁定集群)
Docker node控制集群节点(修改删除节点)
Docker service控制集群的所有服务(启动删除更新扩容服务)
Docker task(不是我们关心的,对于具体容器的创建,维护等)
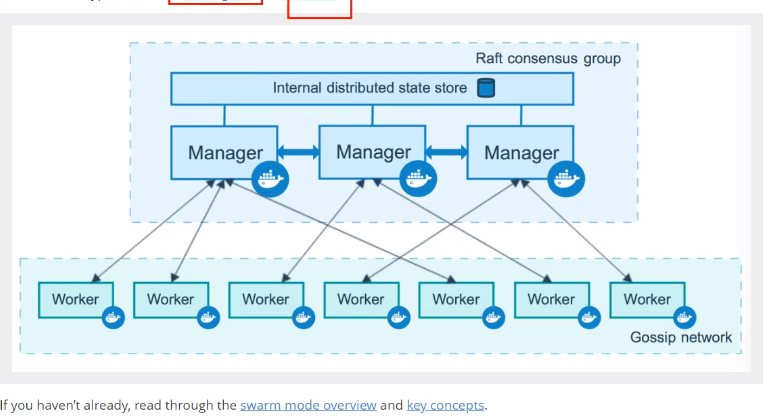
操作都在manager节点上,执行都在工作节点上,搭建集群的时候机器数量一定得是奇数,因为采用了投票机制,半数以上才可以
swam的命令
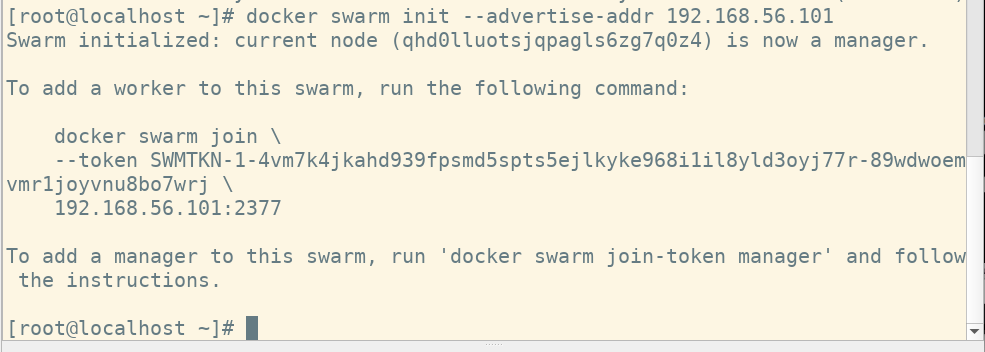
1. 初始化swarm:
1
2
3
| docker swarm init --help #可以看到所有选项
docker swarm init --advertis-addr #初始化一个广播地址
# 这个地址是节点间互相链接的地址分为:公网,私网,基本用私网免费地址即本机的内网IP地址
|
2. 获取令牌
1
2
| docker swarm join-token manager # 管理令牌
docker swarm join-token worker # 工作令牌
|
3. 节点加入
1
2
3
| # 在第二台机器加入一个worker节点
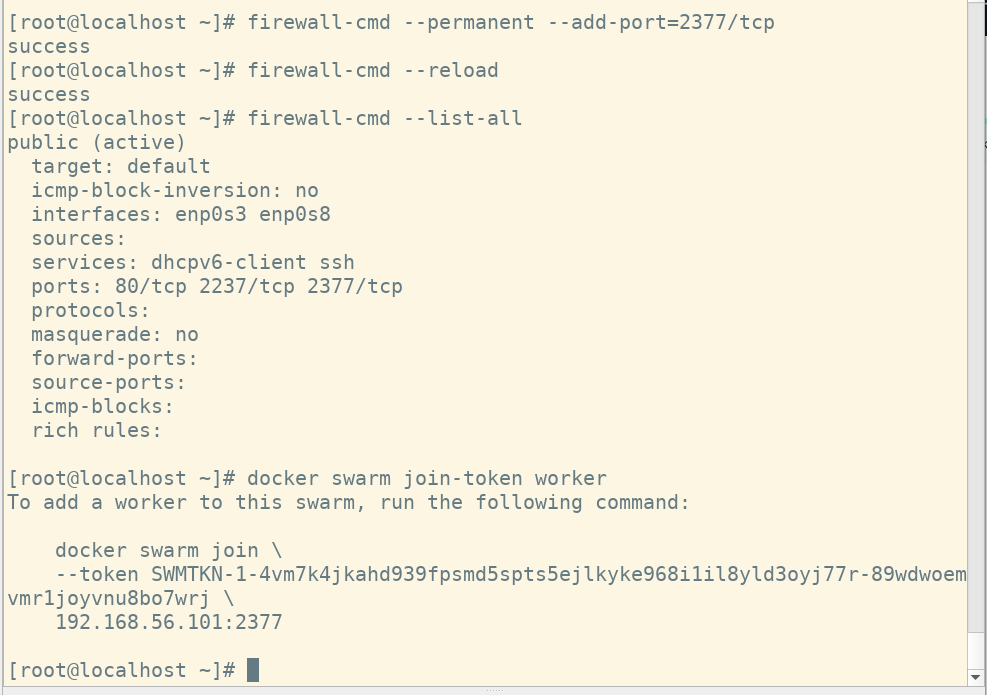
# 注意 被加入的节点需要防火墙允许 2377 端口
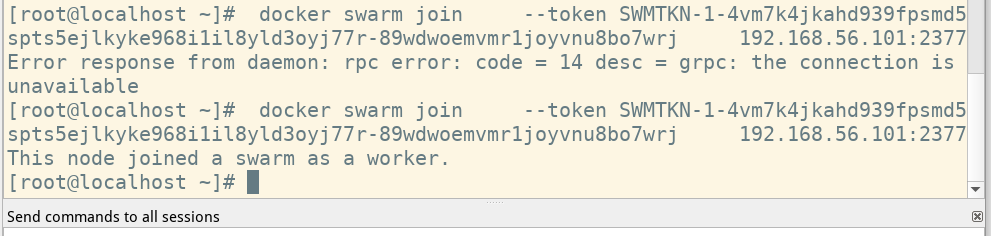
docker swarm join --token SWMTKN-1-4vm7k4jkahd939fpsmd5spts5ejlkyke968i1il8yld3oyj77r-89wdwoemvmr1joyvnu8bo7wrj 192.168.56.101:2377
|
加入管理节点也是同理,管理者需要打开防火墙 2377端口。
主节点管理工作节点:docker node –help
启动服务
关于服务的命令:docker service –help
灰度发布
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| # 创建服务的一些参数
docker service create --help #查看所有参数
-e:# 配置环境变量
-l:# 服务标签
-p:# 暴露端口
-w:# 工作目录
docker service create -p 8888:80 --name mynginx nginx
#会发现和docker run命令很相似,实际上docker run的命令不具有扩缩容,只是个单机架构,docker service会在集群中选择一台服务器启动服务
docker service ls # 查看服务,这是集群的所有服务
docker service ps <具体服务> #查看具体服务的信息
docker service inspect <具体服务> #服务的配置信息,部署在哪台主机上都可以看到
docker service update --help # 动态修改服务的信息,包括扩容缩容等
--replicas # 服务的副本数量
docker service update --replicas 3 mynginx # 给这个服务扩展了两个
docker service scale mynginx=4 # 同replicas的功能
docker service rm <具体服务名> # 移除服务
docker service rollback <服务> # 如果上一次扩容了,回滚到上次
# 全局模式
docker service create --mode global ....# 启动全局服务,不加默认是replicated副本模式
#全局服务不可拓展只有一个,一般可以用来作为中心日志收集服务
|
Docker Stack
docker compose 是单机的,想要集群部署,需要docker stack
1
2
3
| docker-compose up -d xxx.yml # 单机
docker stack deploy xxx.yml # 部署一个可以扩容的服务
|
Docker Secret
安全配置,配置证书密码等
Docker Config
配置
做云的思想
有了docker swarm其实已经可以做云了,举例,用公司机房,加入机房平时不忙,服务器都闲置的时候其实可以搭建好docker swam的集群环境,做个卖vps的页面,用户每次买一个服务器,实际就在docker中新建一个linux虚拟机,副本新增一个,配置给路由器好网络出入站规则,就是一个简单的云了。
负载均衡
部署好后,服务器的任意一个地址都可以访问集群内的服务,这时候一台服务器可以开多个同端口的服务,因为服务之间访问是通过容器名而不是ip+端口,集群内部通过DNS访问service
Docker Swarm 的负载均衡分为两种:
Swarm集群内的service之间的相互访问需要做负载均衡,称为内部负载均衡(Internal LB)
从Swarm集群外部访问服务的公开端口,也需要做负载均衡,称外部部负载均衡(Exteral LB or Ingress LB)
了解 集群节点奇数的原因
转载其他人blog
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| 无论是公司的生产环境,还是自己搭建的测试环境,Zookeeper集群的节点个数都是奇数个。至于为什么要是奇数个,以前只是模糊的知道是为了满足选举需要,并不知道详细的原因。最近重点学习zookeeper,了解到其中的原理,现将其整理记录下来。
首先需要明确zookeeper选举的规则:leader选举,要求 可用节点数量 > 总节点数量/2 。注意 是 > , 不是 ≥。
注:为什么规则要求 可用节点数量 > 集群总结点数量/2 ? 如果不这样限制,在集群出现脑裂的时候,可能会出现多个子集群同时服务的情况(即子集群各组选举出自己的leader), 这样对整个zookeeper集群来说是紊乱的。
换句话说,如果遵守上述规则进行选举,即使出现脑裂,集群最多也只能回出现一个子集群可以提供服务的情况(能满足节点数量> 总结点数量/2 的子集群最多只会有一个)。所以要限制 可用节点数量 > 集群总结点数量/2 。
采用奇数个的节点主要是出于两方面的考虑:
1、防止由脑裂造成的集群不可用。
首先,什么是脑裂?集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的master节点,导致原有的集群出现多个master节点的情况,这就是脑裂。
下面举例说一下为什么采用奇数台节点,就可以防止由于脑裂造成的服务不可用:
(1) 假如zookeeper集群有 5 个节点,发生了脑裂,脑裂成了A、B两个小集群:
(a) A : 1个节点 ,B :4个节点 , 或 A、B互换
(b) A : 2个节点, B :3个节点 , 或 A、B互换
可以看出,上面这两种情况下,A、B中总会有一个小集群满足 可用节点数量 > 总节点数量/2 。所以zookeeper集群仍然能够选举出leader , 仍然能对外提供服务,只不过是有一部分节点失效了而已。
(2) 假如zookeeper集群有4个节点,同样发生脑裂,脑裂成了A、B两个小集群:
(a) A:1个节点 , B:3个节点, 或 A、B互换
(b) A:2个节点 , B:2个节点
可以看出,情况(a) 是满足选举条件的,与(1)中的例子相同。 但是情况(b) 就不同了,因为A和B都是2个节点,都不满足 可用节点数量 > 总节点数量/2 的选举条件, 所以此时zookeeper就彻底不能提供服务了。
综合上面两个例子可以看出: 在节点数量是奇数个的情况下, zookeeper集群总能对外提供服务(即使损失了一部分节点);如果节点数量是偶数个,会存在zookeeper集群不能用的可能性(脑裂成两个均等的子集群的时候)。
在生产环境中,如果zookeeper集群不能提供服务,那将是致命的 , 所以zookeeper集群的节点数一般采用奇数个。
2、在容错能力相同的情况下,奇数台更节省资源。
leader选举,要求 可用节点数量 > 总节点数量/2 。注意 是 > , 不是 ≥。
举两个例子:
(1) 假如zookeeper集群1 ,有3个节点,3/2=1.5 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要2个节点是正常的。换句话说,3个节点的zookeeper集群,允许有一个节点宕机。
(2) 假如zookeeper集群2,有4个节点,4/2=2 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要3个节点是正常的。换句话说,4个节点的zookeeper集群,也允许有一个节点宕机。
那么问题就来了, 集群1与集群2都有 允许1个节点宕机 的容错能力,但是集群2比集群1多了1个节点。在相同容错能力的情况下,本着节约资源的原则,zookeeper集群的节点数维持奇数个更好一些。
|