日语
socketio实时推送
Zookeeper 01
Zookeeper
应用场景
分布式协调组件
服务组件的数据一致性问题的协调,zk可以通知其他服务修改数据状态
分布式锁
zk可以做到强一致性
无状态化的实现
登陆组件(系统)冗余部署后,登录信息放在哪个组件都不行,因为下次自动均衡找到的不一定是上个组件,可以将登录状态放入zk
搭建zk服务器
安装配置
官网下载zk工具
打开进入 bin目录,可以看到zkServer.sh脚本,但是启动是需要zoo.cfg文件的,可以修改conf目录下的zoo_sample.cfg
有了配置文件后
./bin/zkServer.sh start ../conf/zoo.cfg启动即可zoo.cfg 文件说明
1 | zk的时间单位(毫秒) |
zk的基本操作
1 | zkServer.sh start ../conf/zoo.cfg |
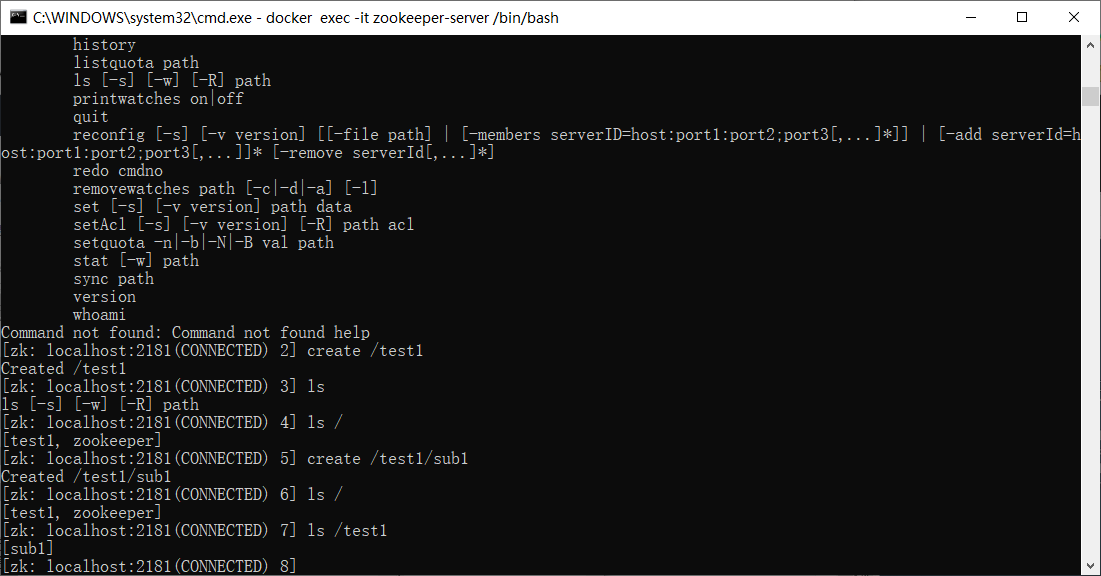
zk内部数据模型
非常类似linux的内部数据结构,每次create都是创建一个node节点,可以给这个node节点内存入数据
znode内部结构包含四个部分:
1. data:数据
2. acl:权限
+ c:create的权限
+ w:写
+ r:读
+ d:删除
+ a:管理
3. stat:描述当前znode的元数据
4. child:当前节点的子节点
zk中节点znode的类型
+ 持久节点:会话结束后任然存在
+ 持久序号节点:每次创建的节点自增序号(并发严重情况下,给每个事务分配顺序)
+ 临时节点:会话结束后即可删除,通过这个实现服务注册和发现(客户端和服务器建立的链接就是一个会话,建立链接时,zk服务器会给zk客户端发送一个session id,每次客户端通信时,zk服务器就会自动续约session id,如果超时自动删除session id这个id可以通过get -s 查看到)
+ Container节点:容器节点,如果容器内没有任何子节点,该节点会被定期删除
+ TTL节点:自定义节点到期时间
zk的数据持久化
- 事务日志:每个执行的命令以日志的形式保存在dataLogDir中
- 数据快照:每隔一定时间把内存的数据备份一次,存在dataDir中
之后恢复可以先回复快照文件数据到内存中,再通过日志文件的数据做增量回复,这样的恢复速度很快
权限设置
注册当前会话的账号密码
addauth digest tr:0800创建节点并且设置权限
create /test abcd auth:tr:0800:cdwra其他会话使用必须执行addauth才能操作
Curator客户端
介绍
- 这是网飞开发的专为zk的客户端框架,是对zk支持最好的工具,支持Leader选举,分布式锁等,减少开发者使用zk的底层细节。
引入依赖
1 | <dependencies> |
application.yml配置文件
1 | =5 |
配置文件WarpperZK.class
1 | package com.zq.client.config; |
CuratorConfig.class 配置文件
1 |
|
测试类文件
1 | package com.zq.client; |
ZK如何实现分布式锁
如果两个java服务都是向数据库中写入车票数据,负载均衡每次只分配到一个java服务,当一个服务写时,另一个服务不能写,如何做到两个或多个服务的锁,通过ZK存储锁
zk中锁的种类:
- 读锁
- 写锁
ZK上读锁
- 创建临时序号节点,节点数据为read,表示读锁
- 获取zk中序号比自己小的所有节点,判断是不是读锁,若都是读锁,那么上锁成功,反之失败,为最小节点设置监听,阻塞等待,当小于最小节点时同时当前节点再判断
ZK上写锁
- 创建临时序号节点,节点数据为write,表示写锁
- 获取所有节点并判断自己是否时最小节点,是则上锁成功,反之监听最小节点,最小节点没了才能再次检测
羊群效应
如果100个并发来上写锁,那么99个并发会监听写锁,当第一个节点完成写锁消失后,99个又触发监听事件,对zk压力大,调整为链式监听即可,即不再监听第一个节点,而是监听上一个节点。
这样,100个并发过来,第一个得到写锁,第二个监听第一个,第三个监听第二个,依次。如果第一个结束,第二个监听事件触发可以上写锁,但是第三位不被触发监听因为第二位节点没有删除。
zk的watch机制
watch机制类似触发器,当znode改变,即调用了create,delete,setData等方法的时候,会触发对应znode上注册的事件,请求watch的客户端会接收到异步通知
cli中创建并且监听节点
1 | craete /test9 |
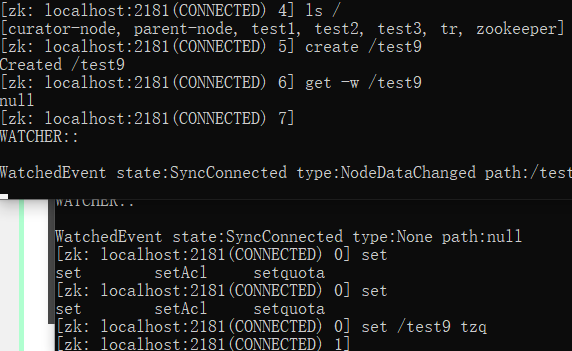
curator 客户端使用watch监听节点
1 | @Test |
Curator 上写锁和读锁
这段junit代码可以先运行读锁再运行写锁看效果
1 |
|
ZK集群
集群的角色
- Leader : 处理集群的所有事务请求,只有一个,负责数据读写
- Follower : 从,只负责数据读,还能参与Leader选举(Leader挂了的情况)
- Observer : 观察者,只负责读,不参与选举
集群搭建
我这里用了docker搭建,没有用dockerCompose,而是bash脚本执行,注意!
在windows下使用gitbash执行shell脚本,路径是要这么写的!
1 | !/bin/bash |
进入集群
docker run -it --rm --network zknet bitnami/zookeeper zkCli.sh -server 192.168.10.28:3181,192.168.10.28:3182,192.168.10.28:3183,192.168.10.28:3184,192.168.10.28:3185
集群实质配置
- 其实本质是每台电脑配置好自己的/bitnami/zookeeper/data目录下的myid(里面是id号)
- 配置/opt/bitnami/zookeeper/conf/zoo.cfg这个cfg文件,最重要的是里面填好通信的其他机器地址和端口
ZAB协议
解决zk的崩溃恢复和主从数据同步问题
ZAB协议定义的四种节点状态
- Looking:选举状态
- Following:Follower节点所处的状态
- Leading:Leader节点的状态
- Observing:。。。
集群上线时Leader选举过程:
启动第一台时会looking状态寻找,直到第二台上线,开始选举,选票(myid,zXid事务id,每次事务都自增)第一轮投票,都生成自己的一张选票,然后把选票信息给对方,每台会比较选票(选择zXid最大的),如果事务id相同,取myid最大的,然后投入投票箱。第二轮互换自己投票箱的票,比较后放入投票箱,选出leader
崩溃恢复时的leader选举
Leader建立完毕后,Leader和Follower是有通信端口的,Leader和Follower存在socket链接,Follower会不间断的读socket数据,Leader会不间断的发,若Leader挂了,socket断开,Follower读不到数据后进入looking状态,其他节点同理。此时Leader出来之前不提供服务!
主从数据同步
客户端向集群写入数据,可能链接的是从,也可能是主,若客户端链接从节点,从节点会将数据发送给主节点。
主节点将数据写入自己的数据文件,并且返回ACK,然后同步的将数据发给Follower(广播),每个从节点也写入自己的数据文件,完成后返回ack给主节点,Leader收到半数以上的Ack信号后,这时Leader给所有从节点提交commit。从节点收到后将数据写入内存。这样大部分服务器数据都同步了。
半数以上是为了提高集群写数据的性能。但是有可能会有某些服务器数据没有写入到内存。
NIO和BIO应用
NIO (多路复用)
- 用于被客户端链接的2181端口
假设同时有4个客户端链接,有读有写,为了性能会使用NIO把所有请求放入一个队列,zk内部处理这些请求- 客户端开启watch时也用
若有客户端同时监听很多znode节点,当节点变化,客户端会被通知到,NIO模式实现非阻塞状态
BIO 传统阻塞模型
- 用于Leader选举时的选票交换
CAP定理
一个系统最多同时满足:一致性(每个节点数据一致),可用性(服务一直可用),分区容错性(遇到节点故障时仍然能够提供服务) 中的两项。
所以现在大部分都采用AP或者AC
BASE理论
- 基本可用 (双十一切掉评论,退款,注册服务,保留核心功能)
- 软状态 (没有其他功能的中间状态)
- 最终一致性 (最终还是能退款的)
回到之前的弊端(zk可能存在某些节点数据未同步),对于未同步数据的服务器,它的事务节点肯定落后于有数据的节点(处理完一次数据,事务id自增),因此zk最求的是顺序一致性,等网络恢复后,落后的节点总会同步到最新的数据,把事务id同步到最新。
Java 工程师之路 四
Java 工程师之路 三
Kafka入门
数据库常用命令
数据库常用命令
1 | 登录数据库: |
Scala-Spark踩坑
Scala Spark 在idea下的错误记录
百度真坑爹,一群人互相抄作业,浪费时间
Object apache is not a member of package org…
idea下,使用默认的scala插件开发
错误描述:这个错误是缺少jar配置文件导致的,但是奇怪的是在linux系统下会出现这个问题,但是windows下使用msi安装sbt不会出现这个问题,idea真神奇
错误解决:
导入spark下的jars(2.0版本后)
下载 spark-assembly-1.6.0-hadoop2.6.0-6.0.0.jar 然后导入即可,这个包包含了全部的集成环境
不要使用maven了,利用sbt构建环境,新建scala项目,右边选择sbt,在打开的build.sbt中写入以下依赖,版本自行决定
1
2
3
4
5
6
7
8
9name := "LearningSparkWithSBT"
version := "0.1"
scalaVersion := "2.11.8"
libraryDependencies ++= Seq(
"org.apache.spark" %% "spark-core" % "2.2.0",
"org.apache.spark" %% "spark-sql" % "2.2.0"
)
NOTE: 版本一定要保持一直,spark和对于的scala版本
Spark 学习 03 原理
Spark 学习 03 spark原理
1.0 总体介绍
为什么说一组电脑是spark集群? 因为这一组电脑都运行了Spark,node01 运行了masterdaemon 所以node01是master,其他电脑运行了workderDaemon,所以其他是worker,workDaemon去master上认领任务,取得任务后还要创建和关闭executor
executor 怎么运行? 首先运行一个executor Backend来管理executor,一对一关系
driver干嘛的? 整个spark application的驱动节点,action操作实质是将结果发给driver
1 | val textRdd: RDD[String] = sc.textFile("data/wordcount.txt") |
2.0 逻辑执行图
代表了数据如何计算和流转,以wordCount为例,在结果调用print(strRdd.toCollectString()),可以看到依赖关系
并非执行单位,最后还是要划分到实际执行单位(机器怎么执行)
2.1 边界
rdd从第一个rdd的创建开始,到逻辑图action执行之前结束.就是一组rdd和其依赖关系
RDD 5大属性:分区,依赖,计算函数,最佳位置,分区函数
2.2 rdd如何生成
sc.textFile在源码中回去生成一个对象:HadoopRdd,这个HadoopRdd继承了父类RDD并且重写了compute方法,这个compute方法实际调用了inputFormat方法,实际就是去读取hdfs文件块,HadoopRdd的一个分区实际就对应了hadoop的一个文件块。
map算子: 在源码中就是new了一个MapPartitionsRdd,且传递了一个scala的map方法给他的构造函数,并且由iter调用。spark map算子中接受的函数,实际交给了里面的scala的map。 这个iter实际是一个分区的迭代器。
flatMap算子:和map差不多
2.3 rdd之间有哪些依赖
rdd分区之间的关系,flatMap这些算子的分区关系是一一对应的
多对一的关系:reduceByKey
为什么要对rdd划分依赖关系:想确定rdd是否能在同一流水线上执行(取决于两个是否是shuffle关系)
窄依赖:没有shuffle,shuffle是必须要对被分发区的每条数据进行切分的
宽依赖:有shuffle,reduceByKey:假设rddA有三个区块的数据,第一个区块的数据为:(hadoop,1),(spark,1),假设生成到rddB,通过分区函数将每个分区的数据发送到rddB的每个分区。然后开始塞数据,假设 key为hadoop的数据给到rddB的0分区,key为spark的hadoop的数据给rddB的1分区。那么rddA的第一个区块的数据会被拆分,所以这是一个宽依赖(shuffle)
如果两个分区一对一关系,必定是窄依赖
如果多对一要看是否有数据分发,有就是宽依赖
窄依赖的类别:
- 依赖类的关系
RDD之间的关系是由 dependency对象决定的,这个对象可以获得另一端信息
第一级别继承类:NarrowDependency,ShuffleDependency
第二级别:OneToOneDependency,RangeDependency,继承自NarrowDependency
- 一对一窄依赖:map算子
- range窄依赖:只在union中使用,两个集合合起来。
- 多对一窄依赖:和shuffle相似但是不是,coalesce求笛卡尔积为例,被发的rdd是不会对数据再切分
宽依赖只能等待前一个rdd的所有数据算好后切割分发,但是窄依赖的不同分区可以和生成的rdd的分区对应放在一个task计算。
3.0 物理执行图
- 数据如何在集群中计算
如代码所示,flatMap和map会被合并为一个计算任务在一个executor中执行完毕后,再执行,一个task表示一个flatMap和map计算,多个task组合成一个stage。
执行shuffle(reduceByKey)操作后就是另一个stage,最后将结果发给Driver。
- RDD是被谁执行计算的?
每台电脑的executor是一个进程,使用多线程计算,和driver认领任务,运行任务线程:task。
task如何设计,如果有rddA—map—>rddB—map—rddC每个rdd都是3个分区。
如果设计每个分区和map就是一个task,那么map的结果得生成文件,给下一个分区的map这就和hadoop的mapreduce一样了
如果将rddA的分区和rddB的分区的两个map生成一个task,一共三个task,共享内存,效率高多了,但是遇到shuffle操作就有问题了。
spark采用数据流动模型设计,划分阶段:因为在遇到shuffle会出问题,所以在有shuffle的地方分段,shuffle左边的某分区的所有操作成为一个task,右边分为一个task,这样就有了两个stage。
划分stage规则:从后往前划分,知道遇到shuffle(宽依赖)断开stage,创建新的stage,继续往前走。
- 数据流向
数据的计算发生在调用Action的RDD上,RDD一直往上请求数据,类似递归,然后不停返回数据。第一个获取数据的rdd是最左边的rdd。
4.0 如何运行
Collect方法会去调用DAGScheduler方法==》taskScheduler方法 运行到集群中。DAGScheduler给每个job生成有向无环图,确定最佳task位置
一次action生成一个job,数据从读取到生成结果就是一个job,job会被分发到集群是spark调度的颗粒,一个job有多个stage,一个stage有多个task,stage之间串行执行。
TaskSet:一个stage对应了一个TaskSet(多个task,数量由分区决定)
5.0 spark 高级特性
闭包
1 | def closeure():Unit = { |